20 Production-Ready ML Architectures on AWS That Will Transform How You Build AI — A Deep Dive Into the Future of Machine Learning at Scale
The Hook
Imagine this:
You're a lead ML engineer at a fintech company. Your fraud detection model works beautifully in your Jupyter Notebook. Precision? 98.7%. Recall? Incredible.
Then you deploy it to production.
And everything... falls apart.
Latency spikes to 2 seconds. Your model drifts within 48 hours. A single GPU instance costs $5,000/month. Compliance wants an audit trail you never built. And the edge devices in retail stores? They can't even run the model offline.
Sound familiar?
Here's the harsh truth: training an ML model is only 10% of the work. The other 90% — deployment, monitoring, governance, scaling, cost optimization, privacy — is where most teams fail.
But what if someone built a complete library of 20 production-ready ML architecture patterns, each aligned with AWS Well-Architected principles, packed with Terraform templates, cost estimates, and battle-tested best practices?
That's exactly what exists. And today, we're going to tear it open.

The Problem
Here's a stat that should terrify every ML team:
87% of data science projects never make it to production.
— Gartner Research
Why? Because the gap between "model that works in a notebook" and "model that runs reliably at scale" is a canyon. And most teams are trying to cross it with a rope bridge.
The challenges are brutal:
- 🔥 Deployment complexity — How do you serve 1M predictions/day with <100ms latency?
- 💰 Cost explosions — GPU instances aren't cheap. A naive deployment can burn $10K/month.
- 🔒 Security & compliance — HIPAA, GDPR, SOC 2... your model needs an audit trail.
- 📉 Model drift — Your model's accuracy decays silently. By the time you notice, damage is done.
- 🌐 Multi-region — Global users need global availability. 99.99% uptime isn't optional.
- 🤝 Privacy — Healthcare consortiums want to collaborate without sharing patient data.
Every one of these challenges requires a different architectural pattern. And each pattern has dozens of AWS services that need to work together perfectly.
Building these from scratch? That's months of work. Per pattern.
Why This Matters
The ML infrastructure market is exploding. And the numbers tell the story:
- The privacy-preserving ML market grew from $2.88B (2024) to $3.82B (2025) and is projected to reach $29.54B by 2032 — a 33.74% CAGR.
- AWS SageMaker is evolving into a unified platform with SageMaker Unified Studio, integrating data governance, AI-powered coding, and ML compute in a single workspace.
- MLOps has gone from buzzword to board-level priority. Companies adopting MLOps best practices report 15-20% optimization in operational spend and 95% reduction in production downtime.
The latest trends shaping enterprise ML in 2025-2026:
| Trend | What It Means |
|---|---|
| SageMaker Unified Studio | One workspace for data + ML + governance |
| LLMOps | Specialized MLOps for LLMs (prompt management, RAG, fine-tuning) |
| Zero-ETL Lakehouse | Eliminate data movement with Apache Iceberg |
| Data-Centric AI | Quality over quantity — better data > bigger models |
| Sustainability in MLOps | Energy-efficient training, carbon-aware scheduling |
| Hyper-Automation | Self-healing models, autonomous retraining pipelines |
⚡ Pro Insight
The companies winning at ML in 2026 aren't the ones with the best models — they're the ones with the best infrastructure. Architecture is the competitive moat.
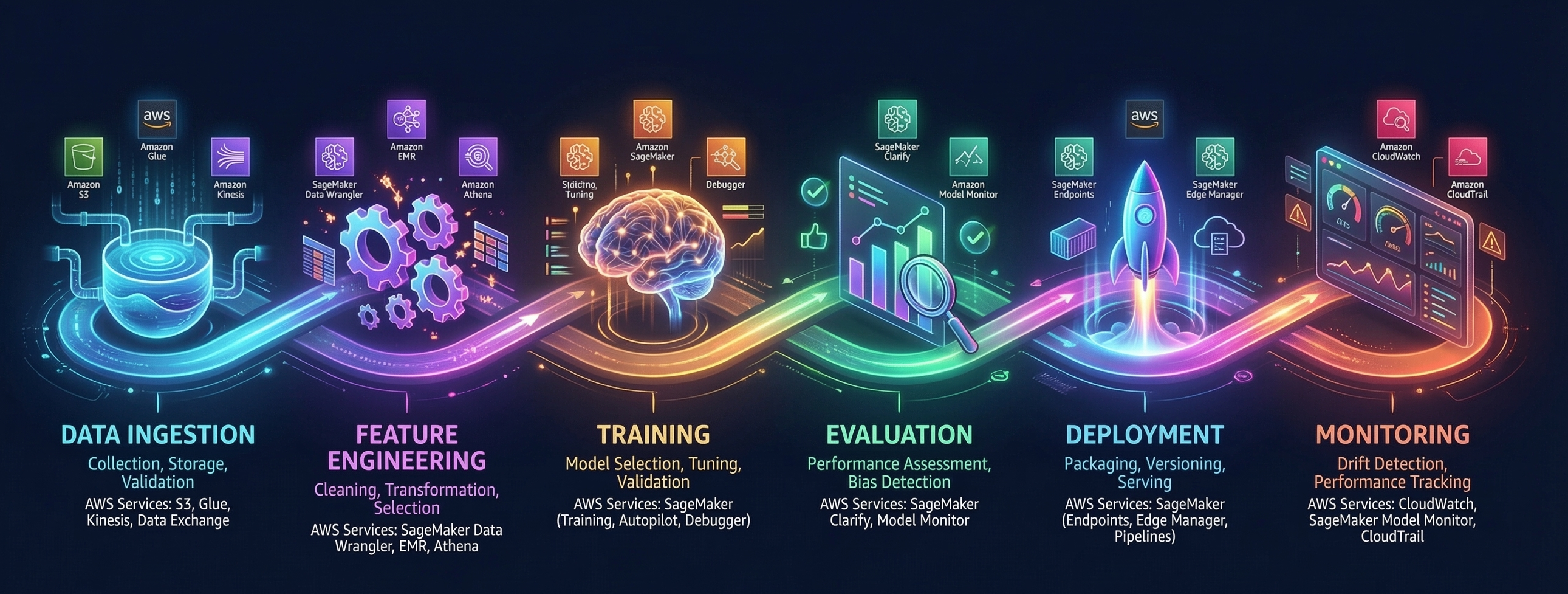
Deep Dive: 20 Architecture Patterns That Cover the Entire ML Lifecycle
Think of building production ML like constructing a skyscraper.
You don't just pour concrete and hope. You need blueprints — for the foundation, the structure, the plumbing, the electrical, the fire safety, the elevator system.
This architecture library is those blueprints. 20 of them. Each covering a critical piece of the ML stack.
Let's walk through the major categories:
🏗️ The Foundation: Data & Feature Engineering
Every skyscraper needs bedrock. For ML, that's your data layer.
Architecture #1 — Data Ingestion & Lakehouse gives you a petabyte-scale data lake with Bronze/Silver/Gold zones:
Raw Zone (Bronze) → Processed Zone (Silver) → Curated Zone (Gold)
↓ ↓ ↓
KMS Encrypted Parquet/ORC Feature-Ready
Versioned Partitioned Optimized
It uses AWS Glue for ETL, Lake Formation for governance, and Athena for querying — all wired together with Step Functions orchestration.
💡 Hidden Gem: The library recommends 128MB-1GB file sizes for optimal Spark performance. Small files (<10MB) crush your query performance. Most teams learn this the hard way.
Architecture #2 — Feature Store solves the "I need the same features in training AND inference" problem. SageMaker Feature Store provides both offline (for training) and online (for low-latency serving) access to the same feature sets. No more training-serving skew.
⚡ The Speed Layer: Training & Inference
This is where compute costs can spiral out of control. The library has six architectures just for this:
| Architecture | Latency Target | Best For |
|---|---|---|
| Online Inference (#5) | <100ms | Real-time fraud detection |
| Batch Inference (#6) | Hours | Scoring 10M records overnight |
| Streaming ML (#7) | <1 second | IoT anomaly detection |
| Edge Inference (#8) | <10ms | Smart cameras, medical devices |
Here's what blew my mind about Architecture #5 (Online Inference):
The flow looks like this:
Client → CloudFront → WAF → API Gateway → Redis Cache → ALB → SageMaker Endpoint
But the details are where the magic lives:
- ElastiCache Redis caches predictions with a 5-minute TTL, targeting >80% cache hit rate — reducing compute costs by 50-80%
- Inferentia instances (ml.inf1) deliver 70% cost savings vs GPUs
- Multi-AZ deployment across 3 availability zones with multi-model endpoints
Estimated cost? ~$705/month for 1M requests/day. That's the price of a junior developer's laptop.
⚡ Pro Insight
Most teams jump straight to GPU instances for inference. But AWS Inferentia (custom silicon) often delivers better throughput at a fraction of the cost. Architecture #5 calls this out explicitly. Don't sleep on Inferentia.

🔄 The Control Tower: MLOps & Governance
Here's a thought experiment:
If your best ML engineer quits tomorrow, could someone else retrain and redeploy your production model from scratch?
If the answer is no, you need Architecture #9 — MLOps CI/CD.
This architecture delivers a 9-stage automated pipeline:
- Source (Git push)
- Build & Test (pytest, linting, security scanning)
- Deploy Infrastructure (Terraform)
- Training Pipeline (SageMaker Pipelines)
- Integration Tests
- Manual Approval (Staging)
- Deploy to Staging
- Manual Approval (Production)
- Canary Deployment (10% traffic → monitor → promote or rollback)
The cherry on top? It costs just ~$31/month for 10 deployments. That's not a typo.
The library also tracks DORA metrics — the gold standard for engineering productivity:
- Deployment frequency
- Lead time for changes
- Mean time to recovery (MTTR)
- Change failure rate
💡 Developer Tip: The architecture uses commit SHA tagging for containers and model artifacts. This means you can trace any production prediction back to the exact code, model, and dataset that produced it. That's not just good engineering — it's audit-proof.
🛡️ The Trust Layer: Privacy, Explainability & Compliance
This is where the library gets really interesting.
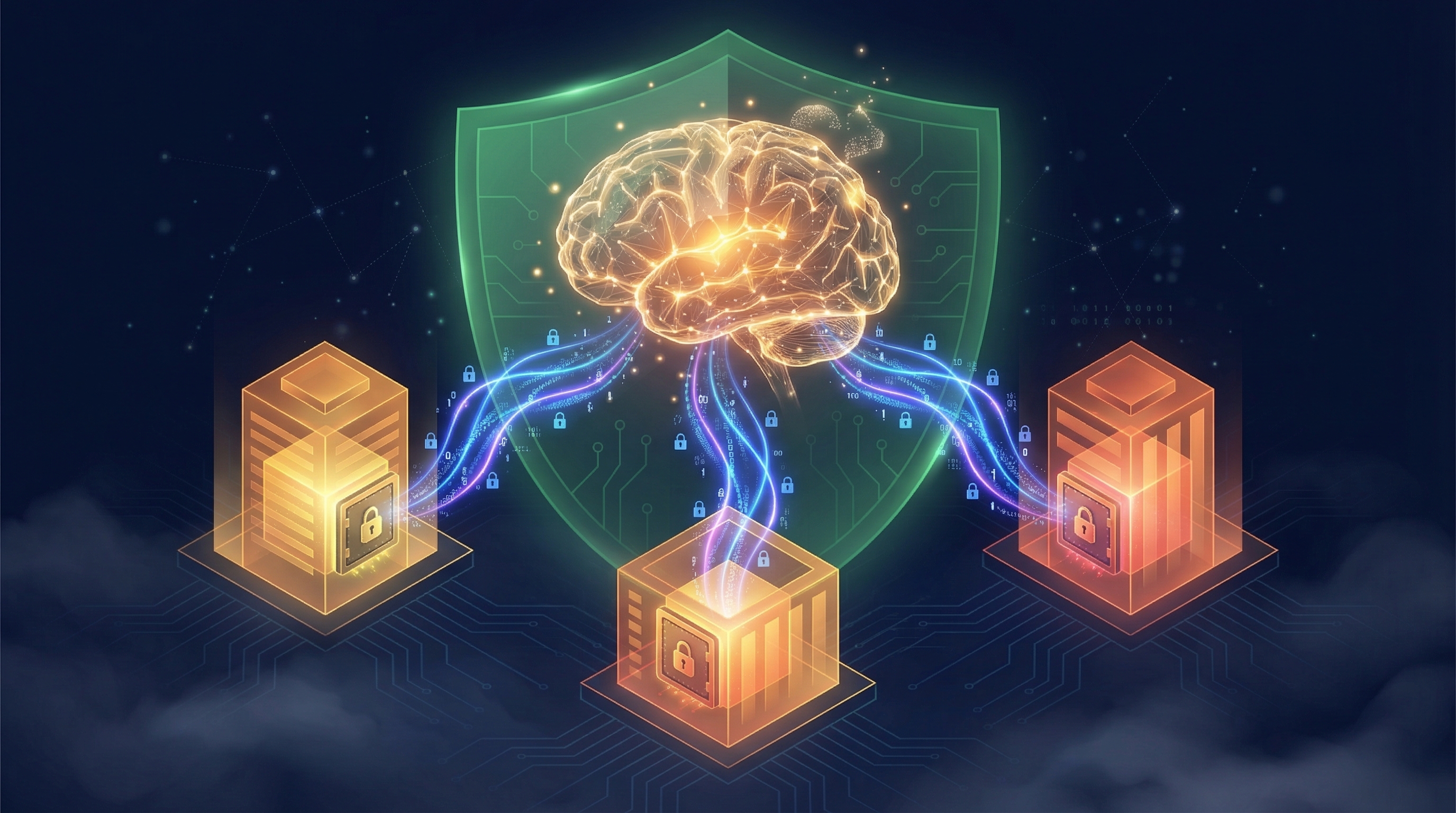
Architecture #15 — Federated & Privacy-Preserving ML solves the "we need data we can't have" problem.
Picture this: Three hospitals want to build a cancer detection model. They have incredible patient data. But HIPAA says they can't share it. Game over?
Not with federated learning:
Hospital A → Train locally → Add differential privacy noise → Send encrypted gradients ─┐
Hospital B → Train locally → Add differential privacy noise → Send encrypted gradients ──┤→ Aggregate → Update Global Model
Hospital C → Train locally → Add differential privacy noise → Send encrypted gradients ─┘
The raw patient data never leaves the hospital. Only encrypted, noise-injected gradients are shared. The result? A model trained on combined knowledge from all three hospitals, with mathematically provable privacy guarantees (ε-differential privacy).
And this is exploding in adoption. The federated learning market is growing at 40%+ annually, with the European Data Protection Supervisor specifically identifying it as crucial for GDPR compliance.
Architecture #12 — Model Explainability leverages SageMaker Clarify for:
- SHAP explanations — why did the model make this prediction?
- Bias detection — is the model discriminating against protected groups?
- Fairness metrics — quantifiable fairness across demographics
⚡ Pro Insight
In regulated industries (finance, healthcare, insurance), model explainability isn't a nice-to-have — it's a legal requirement. If you can't explain why your model denied a loan, you're violating the Equal Credit Opportunity Act.
💰 The Savings Layer: Cost Optimization
Let's talk money.
Architecture #17 — Cost-Optimized ML is a masterclass in cloud economics. The headline number?
70% cost reduction — from $10,000/month to $3,000/month.
Here's the breakdown:
| Strategy | Savings | How |
|---|---|---|
| Spot Instances (Training) | 70% | Checkpoint every 5 min, auto-resume on interruption |
| Inferentia (Inference) | 60% | Custom silicon vs GPU ($0.228/hr vs $0.526/hr) |
| S3 Lifecycle Policies | 80% | Standard → Intelligent-Tiering → Glacier Deep Archive |
| Right-Sizing | 20-40% | Compute Optimizer recommendations |
| Savings Plans | 40% | 1-3 year commitment for baseline workload |
The secret sauce? Layering these strategies together. Spot for training + Inferentia for inference + auto-scaling + lifecycle policies = compound savings.
💡 Developer Tip: Always enable checkpointing when using Spot instances. Without it, a Spot interruption means starting your training from scratch. With it, you resume in minutes. The architecture specifies 5-minute checkpoint intervals — that's the sweet spot between safety and performance.

Inside the Project: Hidden Insights Most Developers Miss
After deep-diving into all 20 architecture files, here are the insights that surprised me most:
1. The 23-Section Standard
Every single architecture follows an identical 23-section structure:
- Problem Statement
- When to Use / When NOT to Use
- AWS Well-Architected Alignment (all 6 pillars!)
- Components & Services
- ASCII Diagrams
- Security Controls
- Data Governance
- Monitoring & Observability
- Cost Estimates
- Compliance Controls
- DR & Reliability
- ...and 12 more sections
This isn't documentation — it's a production readiness checklist. If your ML system doesn't have answers for all 23 sections, you're not ready for production.
2. The Industry Matrix Is a Cheat Code
The industries.md file maps every architecture to specific industries with explicit "When to Use"
and "When NOT to Use" guidance:
| Industry | Primary Architectures | Critical Focus |
|---|---|---|
| Financial Services | #02, #05, #07, #10, #11, #12, #15, #19 | Low latency, compliance, fraud detection |
| Healthcare | #02, #08, #10, #11, #12, #15, #19 | HIPAA, federated learning, edge deployment |
| Manufacturing | #03, #07, #08, #11, #20 | Predictive maintenance, robotics, edge inference |
| Automotive | #04, #08, #18, #20 | Autonomous driving, RL training, simulation |
Want to build ML for healthcare? Start with architectures 02, 08, 10, 11, 12, 15, and 19. The matrix does the thinking for you.
3. Cost Estimates Are Shockingly Transparent
Every architecture includes monthly cost estimates. Some favorites:
- MLOps CI/CD pipeline: $31/month (for 10 deployments)
- Model Registry & Governance: $55/month
- Edge Inference: $250/month (for 1,000 devices!)
- Batch Inference: $28 per 10 million records
- Monitoring & Drift Detection: $130/month
These aren't marketing numbers. They're detailed breakdowns by service: "S3 Storage: $230, Glue ETL: $440, Athena: $50."
4. The Graph ML Pattern Is Underrated
Architecture #19 — Graph ML & GNN Pipelines uses Amazon Neptune for graph neural networks. This pattern is perfect for:
- Fraud rings detection (seeing connections between accounts)
- Drug discovery (molecular interaction graphs)
- Social network analysis
- Knowledge graphs
Most teams default to tabular ML. But when your problem is fundamentally about relationships, Graph ML outperforms everything else.
5. Reinforcement Learning Meets the Physical World
Architecture #20 — RL Training & Sim-to-Real connects AWS RoboMaker with SageMaker RL for autonomous systems. Train in simulation, deploy to real robots. The estimated cost? ~$800/month per training run.
Key Takeaways
Let's distill everything into actionable insights:
1. Architecture > Algorithms
The best model in the world fails without proper infrastructure. Start with architecture patterns, then optimize
models.
2. Cost Optimization Is Multiplicative
Layering Spot instances + Inferentia + auto-scaling + lifecycle policies = 60-80% savings. Don't just use one
strategy — use all of them.
3. Federated Learning Is Production-Ready
The $29.54B projected market by 2032 isn't hype — enterprises are deploying this today. If you work in
healthcare or finance, this is your future.
4. MLOps for $31/month Is Real
A fully automated CI/CD pipeline with canary deployments, approval gates, and DORA metrics — for the cost of
lunch. There's no excuse not to have this.
5. The 23-Section Checklist Is Your North Star
If you can't answer all 23 sections for your ML system, you have gaps. Use the checklist as a production
readiness audit.
6. Don't Ignore Edge & Graph ML
Edge inference ($250/month for 1K devices) and Graph ML are massively underutilized. If your use case fits, the
ROI is enormous.

Final Thoughts
We're at an inflection point.
The tools for production ML have never been more mature. AWS SageMaker is evolving into a unified platform. MLOps is automating everything from retraining to rollback. Federated learning is making privacy and collaboration compatible. And cost optimization techniques are slashing bills by 70%.
But tools alone aren't enough. You need architecture patterns — proven blueprints that connect these tools into production-ready systems.
This library of 20 architectures isn't just documentation. It's a cheat code for the 90% of ML work that happens after the model is trained.
Whether you're deploying fraud detection at sub-100ms latency, training a cancer detection model across hospitals without sharing patient data, or cutting your ML infrastructure costs from $10K to $3K/month — there's a pattern for that.
The question isn't whether your next ML project needs production architecture.
The question is: which of the 20 patterns will you use first?
🚀 If you found this useful. Share it with your ML team. Bookmark it for your next architecture review. And if you've deployed any of these patterns in production — I'd love to hear your story in the comments.
Written with insights from the AWS ML Architecture Library, AWS Well-Architected Framework, and the latest industry research on MLOps, federated learning, and cloud-native ML infrastructure.
📌 Connect & Support
🐙 GitHub Repository: View Source Code + Terraform templates
📧 Email: connect@jaydeepgohel.com — Let's connect and discuss cloud architecture
☕ Buy Me a Coffee: If you found this work valuable and want to support more content like this, buy me a coffee ☕
This article was written with a little help from AI
💬 Feedback: Share your thoughts in the comments below — What did you love? What can be improved? Your feedback helps me create better content! 👇


Comments
Post a Comment