Why Your Next Data Pipeline Will Probably Fail (And How 33 Battle-ready Architectures Can Save You)
Here's a question: Have you ever built a data pipeline that worked perfectly... until it didn't?
Maybe it was the 3 AM page when your "simple" batch job suddenly took 12 hours instead of 2. Or that moment when Legal asked if your pipeline is HIPAA-compliant and you realized you had no idea what that even meant.
Yeah. We've all been there.

The $3 Million Question Nobody Asks
Let me tell you about Sarah. She's a senior data engineer at a mid-sized healthcare company. Last year, her team spent six months building a "modern" data lake on AWS. Beautiful architecture diagrams. Clean code. Everyone was proud.
Then came the audit.
Turns out, their entire pipeline violated HIPAA regulations. Patient data was sitting in S3 buckets without proper encryption. Access logs? Incomplete. Data lineage? "What's that?"
The fix? $3.2 million in consulting fees, a complete rebuild, and Sarah's team working weekends for four months.
Here's the kicker: All of this could have been avoided with the right architecture from day one.
Pause and think 🤔
When was the last time you chose an ETL architecture based on compliance requirements FIRST, rather than "what's cool" or "what we know"?
The Hidden Truth About Data Pipelines in 2026
Here's what nobody tells you when you're starting out:
Building a data pipeline isn't hard. Building one that survives real-world chaos is.
In 2026, the data landscape has evolved into something beautifully complex and terrifyingly fragile:
- AI is everywhere - Your pipeline isn't just moving data anymore; it's feeding ML models that make real-time decisions
- Multi-cloud is the norm - 73% of enterprises now use 2+ cloud providers (not by choice, but by acquisition and necessity)
- Regulations are tightening - GDPR fines hit €1.6 billion in 2025 alone
- Real-time is expected - Batch processing overnight? Your competitors are making decisions in milliseconds

Quick reality check ✋
Which of these sounds familiar?
- "We'll add compliance later"
- "Real-time is too expensive for us"
- "We're AWS-only, so multi-cloud doesn't matter"
- "Our data is simple, we don't need a medallion architecture"
If you nodded to any of these... keep reading. You're about to save yourself a LOT of pain.
The Architecture Library You Didn't Know You Needed
Imagine having a playbook with 33 production-ready ETL architectures across AWS, Azure, and GCP.
Not theoretical diagrams. Not "hello world" examples. Battle-tested patterns that handle:
- ✅ 11 core patterns (Batch, Streaming, Real-time, CDC, IoT, ML Features, and more)
- ✅ 3 major clouds (AWS, Azure, GCP - with actual service mappings)
- ✅ 10+ industries (Banking, Healthcare, E-commerce, Gaming, FinTech, etc.)
- ✅ 9 compliance frameworks (HIPAA, GDPR, PCI DSS, SOX, and more)
This isn't vaporware. This is what happens when someone actually documents the patterns that work in production.
Try this experiment 🧪
Open your current data architecture diagram. Now ask yourself:
- Can you trace a single record from source to destination? (Data lineage)
- What happens if one component fails at 2 AM? (Fault tolerance)
- Could you prove compliance in an audit tomorrow? (Governance)
If you hesitated on any of these... you need better architecture patterns.
Let's Get Real: The Medallion Architecture
You've probably heard of the "Bronze-Silver-Gold" pattern. But do you really understand why it's brilliant?
Most people think: "Oh, it's just organizing data into layers."
Reality: It's a progressive quality filter that saves your ass when things go wrong.
Here's how it actually works:
🥉 Bronze Layer: The Truth Serum
- Raw data, exactly as it arrived
- Immutable and complete
- Your insurance policy when someone says "the source system changed and we lost data"
🥈 Silver Layer: The Cleanup Crew
- Validated, deduplicated, standardized
- Where you fix the mess before anyone sees it
- SCD Type 2 for historical tracking (because yes, you WILL need to know what the data looked like last Tuesday)
🥇 Gold Layer: The Business View
- Aggregated, enriched, optimized
- Star schemas for BI tools
- Sub-second query performance

The moment of truth 💡
Question: Your CEO asks why last quarter's revenue numbers don't match the source system.
- Without Medallion: Panic. Finger-pointing. "The data changed."
- With Medallion: "Let me check Bronze... ah, the source system had a bug on March 15th. Here's the exact record."
Which scenario would you rather be in?
Streaming vs. Batch: The $500K Decision
Here's a conversation I overheard at a conference:
Engineer 1: "We're moving everything to real-time streaming!"
Engineer 2: "Why?"
Engineer 1: "Because... it's modern?"
Facepalm moment.
The Real Decision Matrix
Use Batch ETL when:
- You're processing terabytes of historical data
- Nightly reports are fine
- Cost optimization > speed
- Example: Daily financial reconciliation for a bank
Use Streaming ETL when:
- Data arrives continuously
- You need insights in seconds/minutes
- Event-driven architecture
- Example: Clickstream analytics for e-commerce personalization
Use Real-Time ETL when:
- Latency must be < 100ms
- Synchronous request-response
- Lives or money are on the line
- Example: Fraud detection for credit card transactions
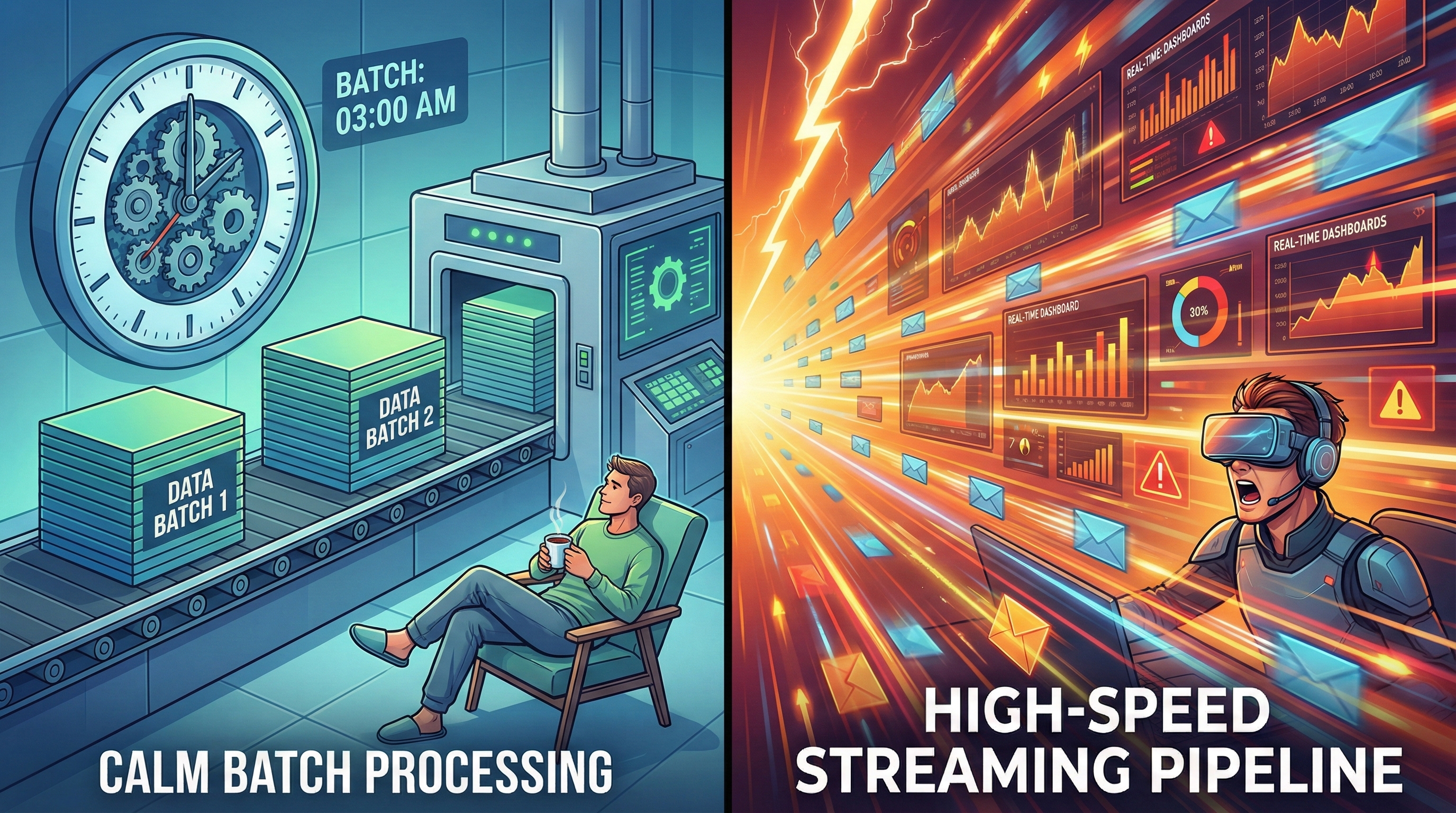
Here's the truth bomb 💣
Real-time streaming costs 3-5x more than batch processing.
So before you architect for milliseconds, ask: "What's the actual business cost of waiting 5 minutes?"
For Netflix recommendations? Probably fine.
For autonomous vehicle decisions? Not so much.
The Compliance Trap (And How to Avoid It)
Let's talk about the elephant in the room: compliance.
Most engineers treat compliance like vegetables - they know it's important, but they'd rather not deal with it.
The Banking Nightmare Scenario
Imagine you're building a data pipeline for a bank. You need to handle:
- SOX: Audit trails for every data change
- PCI DSS: Encryption for cardholder data
- GDPR: Right to erasure for EU customers
- Basel III: Risk data aggregation and reporting
Now here's the fun part: These requirements often conflict.
GDPR says "delete customer data on request." SOX says "keep immutable audit logs forever."
How do you solve this? 🤯

The Architecture Solution
Medallion + CDC + Audit Logging
- Bronze: Immutable source data (SOX ✅)
- Silver: Masked PII with tokenization (PCI DSS ✅)
- Gold: Business views with data retention policies (GDPR ✅)
- CDC Pipeline: Real-time replication for fraud detection
- Separate Audit Store: Compliance logs in append-only storage
This isn't theoretical. This is Pattern #7 in the library, tested in production at multiple Fortune 500 banks.
Your turn 🎯
Think about your current pipeline:
What compliance frameworks apply to your industry? (Hint: If you don't know, that's a problem.)
Multi-Cloud: The Strategy Nobody Wanted (But Everyone Needs)
Real talk: Nobody wakes up and says "I want to manage data across AWS, Azure, AND GCP!"
But here's what actually happens:
- Your company acquires another company (they use Azure, you use AWS)
- Your biggest client demands GCP for data residency
- AWS has an outage and your CEO asks "why aren't we multi-cloud?"
Suddenly, multi-cloud isn't a choice. It's survival.
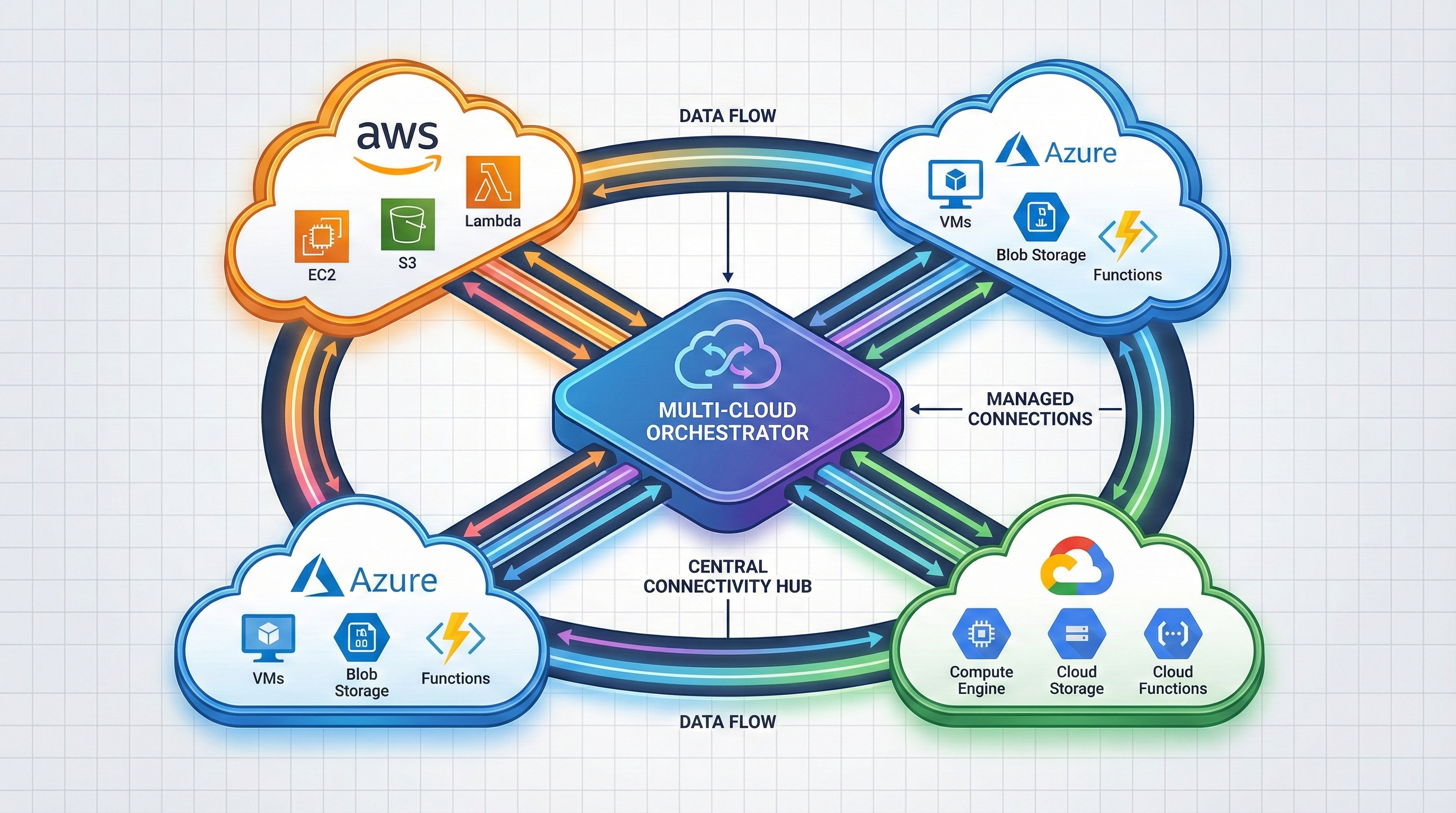
The Smart Multi-Cloud Strategy
Don't: Try to build identical pipelines on each cloud
Do: Use each cloud's strengths strategically
- AWS: Best for broad service catalog and mature ecosystem (Glue, EMR, Redshift)
- Azure: Best for enterprise integration and Microsoft stack (Synapse, Databricks, Purview)
- GCP: Best for AI/ML and analytics (BigQuery, Vertex AI, Dataflow)
Example: A gaming company uses:
- GCP for player analytics (BigQuery's speed)
- AWS for game servers (EC2 flexibility)
- Azure for backend services (existing .NET infrastructure)
Challenge time 🏆
If you had to move your current pipeline to a different cloud provider tomorrow, how long would it take?
- Less than a week? You're cloud-agnostic (rare!)
- A month? You're doing okay
- "We'd have to rebuild everything"? You're vendor-locked (very common)
The Industry-Specific Secret Sauce
Here's something fascinating: The same ETL pattern looks completely different across industries.
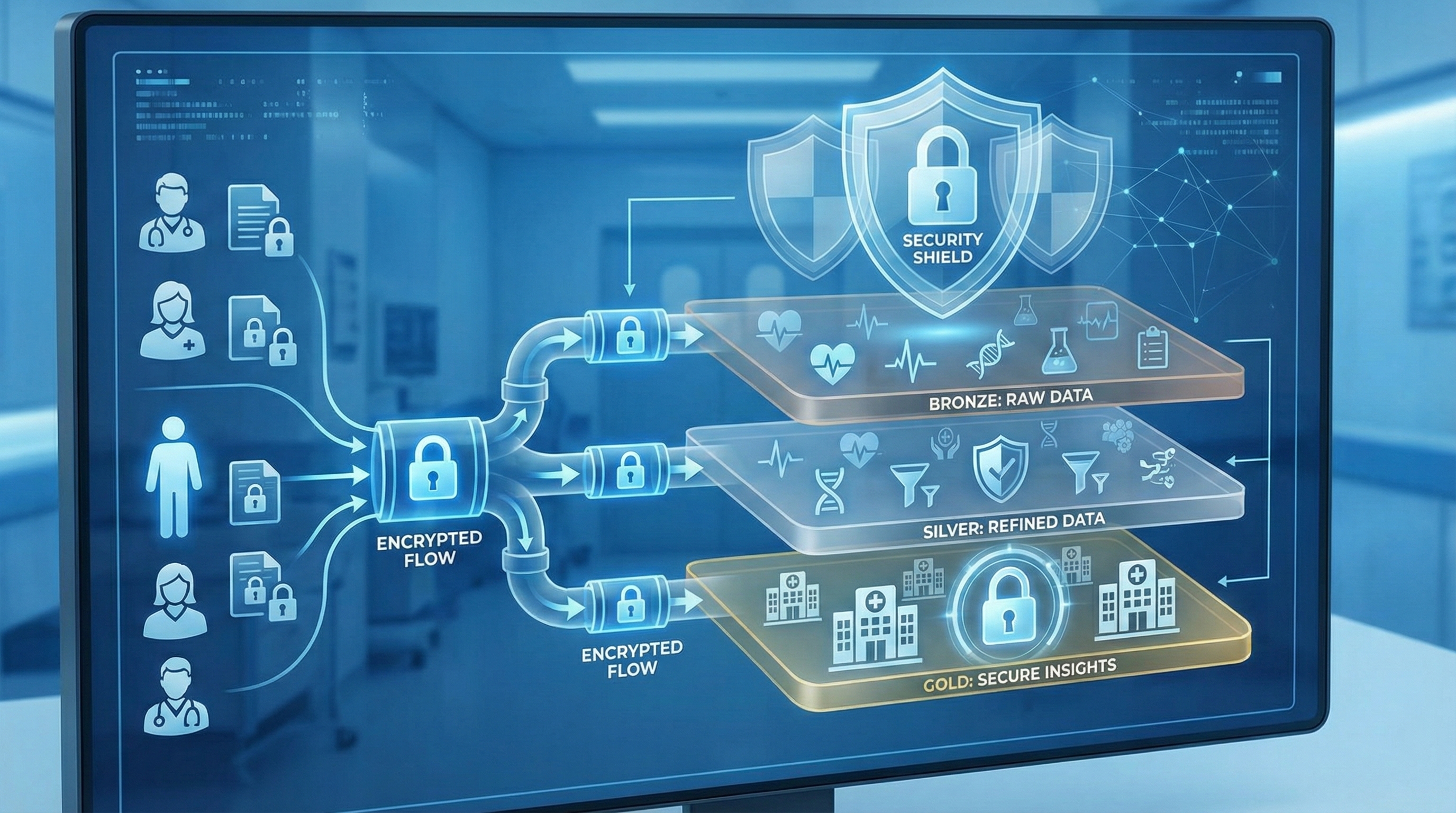
Healthcare: The HIPAA Minefield
Challenge: Patient data is sacred. One breach = millions in fines + destroyed reputation.
Architecture: Medallion + IoT + ML Features
- Bronze: Raw EHR data from hospitals
- Silver: De-identified PHI for analytics
- Gold: Clinical insights for doctors
- Special sauce: Every data access logged, encrypted at rest AND in transit, BAA with cloud provider
E-Commerce: The Real-Time Race
Challenge: Recommend products in < 100ms or lose the sale.
Architecture: Real-Time ETL + Streaming + ML Features
- Lambda/Functions for instant processing
- DynamoDB/Cosmos DB for sub-10ms reads
- Feature Store for personalization models
- Special sauce: Caching layers, pre-computed aggregations, A/B testing built-in
FinTech: The Fraud Fighter
Challenge: Detect fraud before the transaction completes.
Architecture: Streaming + CDC + Real-Time
- Kafka/Event Hubs for transaction streams
- Real-time ML scoring (< 50ms)
- CDC for customer 360 view
- Special sauce: Exactly-once processing, distributed tracing, circuit breakers
What's YOUR industry's secret? 🔍
Think about it: What makes data pipelines in your industry unique? Is it compliance? Speed? Scale? Data variety?
The Patterns You'll Actually Use
Let's cut through the noise. Here are the 5 patterns that solve 90% of real-world problems:
1. Medallion Data Lake 🏛️
When: You need data quality + governance + flexibility
Industries: Banking, Healthcare, Manufacturing
Cloud: All three (S3 + Glue, ADLS + Databricks, GCS + Dataflow)
2. Streaming ETL 🌊
When: Continuous data flow, seconds-to-minutes latency
Industries: E-commerce, Gaming, Telecom
Cloud: Kinesis (AWS), Event Hubs (Azure), Pub/Sub (GCP)
3. Real-Time ETL ⚡
When: Millisecond latency, synchronous processing
Industries: FinTech, Gaming, Ad Tech
Cloud: Lambda + DynamoDB, Functions + Cosmos DB, Cloud Functions + Firestore
4. CDC (Change Data Capture) 🔄
When: Real-time database replication, zero downtime migration
Industries: Banking, Healthcare, E-commerce
Cloud: DMS + MSK, Data Factory + Event Hubs, Datastream + Pub/Sub
5. ML Feature Pipelines 🤖
When: Training-serving consistency, feature reuse
Industries: All industries with ML
Cloud: SageMaker Feature Store, Azure ML Feature Store, Vertex AI Feature Store
Mini-challenge 🎮
Match your current project to one of these patterns.
If it doesn't fit... you might be overengineering (or underengineering). Both are expensive mistakes.
The Cost Conversation Nobody Wants to Have
Let's talk money. Because at the end of the day, your architecture is a business decision.
The Real Cost of Bad Architecture
Scenario: You built a batch ETL pipeline that runs every hour.
Problem: Business wants real-time.
Options:
- Rebuild from scratch: $500K + 6 months
- Hybrid approach: $150K + 2 months (if you planned for it)
- Impossible: If you hardcoded batch assumptions everywhere
The lesson? Architecture decisions have a half-life of 3-5 years.
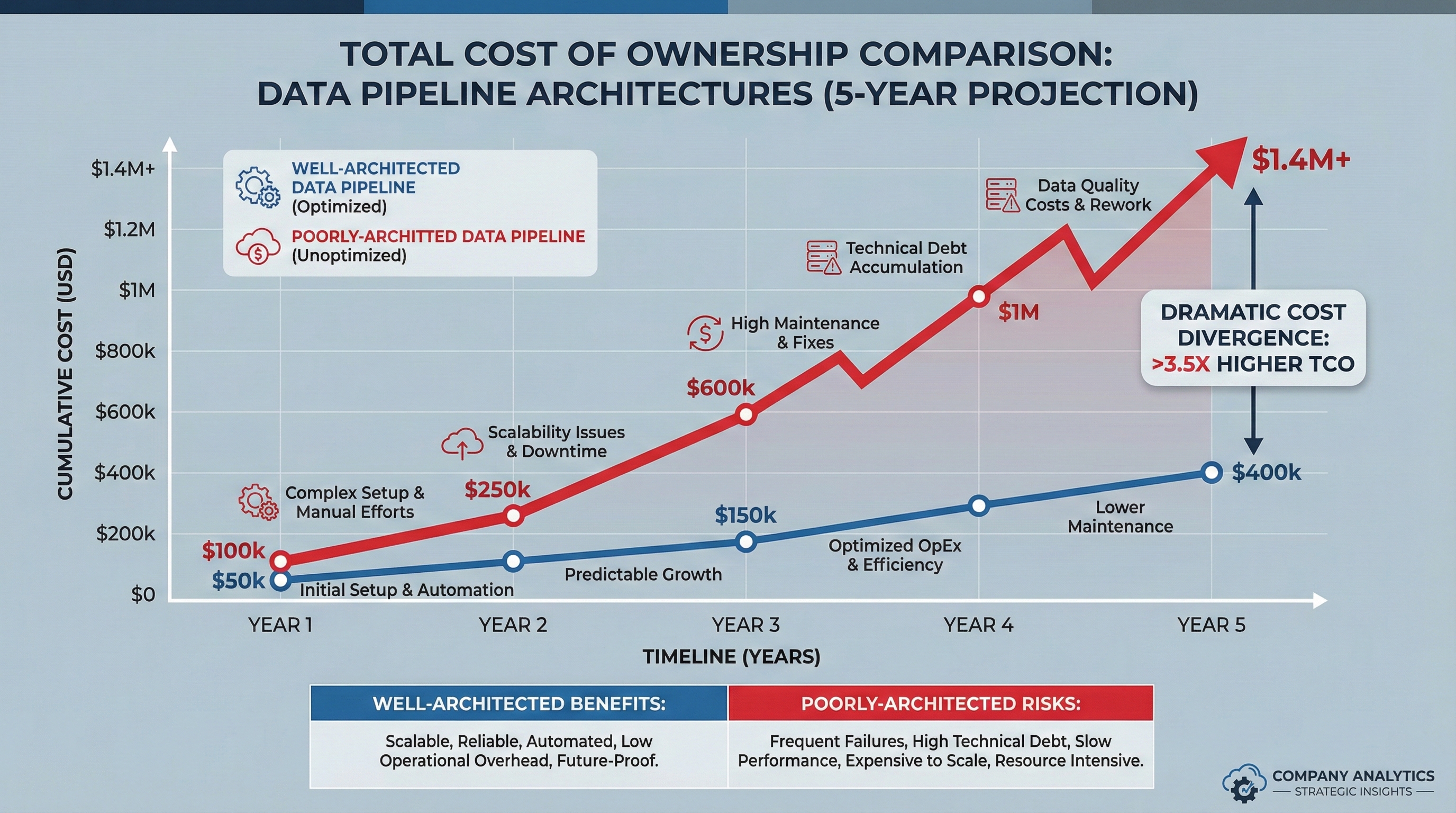
Cost Optimization Secrets
Batch ETL:
- Use Spot/Preemptible instances (80% savings)
- Schedule during off-peak hours
- Compress data (Parquet = 10x smaller than CSV)
Streaming ETL:
- Enable autoscaling (pay for what you use)
- Use FlexRS on Dataflow (40% discount)
- Implement backpressure handling
Real-Time ETL:
- Cache aggressively
- Pre-compute aggregations
- Use reserved capacity for predictable workloads
The $1M question 💰
What's more expensive: building it right the first time, or rebuilding it later?
(Hint: It's always the rebuild.)
What Actually Matters (The TL;DR)
If you remember nothing else from this article, remember this:
✅ Start with compliance, not technology
Your architecture must survive audits, not just demos.
✅ Choose patterns based on latency requirements
Batch, Streaming, or Real-time? The business case decides, not the hype.
✅ Medallion architecture is your safety net
Bronze-Silver-Gold isn't just organization; it's insurance.
✅ Multi-cloud is inevitable
Design for portability from day one.
✅ Industry-specific patterns exist for a reason
Healthcare ≠ E-commerce ≠ Banking. Don't copy-paste.

Your Next Move
Here's the thing about data pipelines: You can't avoid building them, but you CAN avoid building them wrong.
The 33 architectures in this library aren't just documentation. They're battle scars turned into blueprints.
Every pattern has been tested in production. Every compliance requirement has been validated. Every cost optimization has been measured.
Three questions to ask yourself right now:
- Does my current architecture have a name? (If not, you're probably reinventing the wheel)
- Can I explain my compliance strategy in one sentence? (If not, you're at risk)
- What happens if my cloud provider has an outage tomorrow? (If you don't know, you're not ready)

Let's Talk
I want to hear from you:
- What's the biggest data pipeline disaster you've survived?
- Which architecture pattern are you using (or should be using)?
- What compliance nightmare keeps you up at night?
Drop a comment below. Let's learn from each other's mistakes (and wins).
And if you found this helpful, share it with that engineer on your team who's about to make a very expensive architecture decision.
You might just save them $3 million. 😉
P.S. - If you're thinking "I need to see these architectures in detail," you're in luck. The full library includes:
- 33 detailed architecture documents
- Cloud-specific service mappings
- Compliance checklists
- Cost comparison tables
- Sample code and IaC templates
Because good architecture isn't about being clever. It's about being prepared.



Comments
Post a Comment